
Under the guidance of Professor Shan Caifeng, the vice dean, and Assistant Professor Si Chenyang, our 2025 doctoral student Dong Wenhui and research assistant Zhao Ming have proposed SpineGPT, a large model for spinal diagnosis and treatment. This research has collaborated with many renowned doctors from the General Hospital of the People's Liberation Army, the Second Affiliated Hospital of Zhejiang University, and Huashan Hospital, and has brought together multiple forces from industry, academia, and research, including Pi3Lab and Shanghai Sino Medical Instrument Co., Ltd., to jointly complete the development of the first large model for the field of spinal diagnosis and treatment.
Spinal diseases affect 619 million people worldwide and are one of the main causes of disability. However, there is still a cognitive gap in the clinical decision-making of existing AI models. The lack of level-aware, multimodal fusion instruction data and standardized benchmarks is the key bottleneck restricting the development of AI-assisted diagnosis.
This paper presents a comprehensive solution, including the first large-scale and traceable spinal instruction dataset SpineMed-450K, as well as the clinical-level evaluation benchmark SpineBench. The specialized large model SpineGPT trained based on this has achieved significant improvements in all tasks. With only 7 billion parameters, it has comprehensively surpassed top open-source large models such as GLM-4.5V and Qwen2.5-VL-72B.

Paper Title:SPINEBENCH: A CLINICALLY SALIENT, LEVEL-AWAREBENCHMARK POWERED BY THE SPINEMED-450K COR-PUS
Paper Link:https://arxiv.org/pdf/2510.03160
I. Clinical Pain Point: The Cognitive Gap of General LVLMs
The clinical diagnosis and treatment of spinal diseases require a complex reasoning process: integrating findings from multiple modalities such as X-rays, CT, and MRI, and precisely locating the lesion to a specific vertebral level (Level-Aware Reasoning) to determine the severity and plan intervention measures. This integrated reasoning ability is a systematic weakness of existing general vision-language large models (LVLMs).
This weakness was fully exposed in the SpineBench evaluation:

The performance gap is significant: Even Qwen2.5-VL-72B, with 72 billion parameters, has an average performance of only 79.88%. There is still a nearly 6-percentage-point gap between the leading open-source model GLM-4.5V (83.26%) and the top proprietary model Gemini-2.5-Pro (89.23%). In the medical report generation task, the gap is even more pronounced, with Qwen2.5-VL-72B lagging behind Gemini-2.5-Pro by 30%.
Cross-modal alignment deficiency: The performance of almost all models on multimodal tasks has declined to varying degrees. For instance, the gap between GPT5's performance in pure text QA (87.41%) and image QA (79.97%) is as high as 7.44 percentage points. This reflects the fundamental insufficiency of existing models in medical image understanding and visual-language alignment, which limits their application in clinical scenarios that require comprehensive analysis of both images and text.
II. Core Achievements: Building the Infrastructure for Clinical-grade AI
To bridge the cognitive gap between existing data and clinical needs, the research team, in collaboration with spine surgeons in practice, jointly designed and constructed the SpineMed ecosystem.
SpineMed-450K: A Vertebral-level, Multi-modal Instruction Dataset
This is the first large-scale dataset explicitly designed for vertebral-level reasoning.

Scale and source: Contains over 450,000 instruction instances. The data sources are extremely rich, including textbooks, surgical guidelines, expert consensuses, open datasets (such as Spark, VerSe 20202020), and approximately 1,000 de-identified real multimodal hospital cases. The real cases originated from 11 well-known domestic hospitals, ensuring the diversity of patient sources.
Generation pipeline: Data generation adopts a rigorous Clinician in-the-loop process. This process involves:
Extract graphic and text information using PaddleOCR.
Through a new image-context matching algorithm, the image is precisely bound to its surrounding text context to ensure traceability.
High-quality instruction data was generated by using the LLM two-stage generation method (drafting and revision), and clinicians participated in the review of the prompt word strategy and revision standards.

Task diversity: It covers four types: multiple-choice QA (249k), open-ended QA (197k), multi-round diagnosis and treatment dialogue (1.1k), and clinical report generation (821 cases). The data covers seven orthopedic subspecialties, among which spinal surgery accounts for 47% and is further subdivided into 14 types of spinal subdiseases.

2. SpineBench: The first benchmark for evaluating clinical significance
SpineBench is an evaluation framework deeply integrated with clinical practice, aiming to assess the types of errors that AI makes in fine-grained, anatomically centered reasoning, which are crucial in practice.
The benchmark composition ultimately includes 487 high-quality multiple-choice questions and 87 report generation prompts.
Rigorous verification: To ensure the completeness of the assessment set, a team of 17 orthopedic surgeons was divided into three independent groups to conduct rigorous verification and correction.
Report Evaluation: A framework calibrated by experts was designed for the task of generating clinical reports. The assessment is conducted from five major sections and ten dimensions:
I. Structured Imaging Report (SIP) : Evaluate the accuracy, clinical significance, and quantitative description of the findings.
II. Ai-assisted Diagnosis (AAD) : Evaluate the correctness of the primary diagnosis, differential diagnosis, and clinical reasoning.
III. Treatment Recommendations (TR) : They are divided into patient guidance (language clarity, empathy, comfort), evidence-based planning (reasons, guideline consistency), and technical feasibility (surgical details, complication prevention).
IV. Risk and Prognosis Assessment (RPM) : Evaluate perioperative management, follow-up arrangements, and strategies for potential problems.
V. Reasoning and Disclaimer (RD) : Evaluate the coverage of evidence, relevance, granularity of detail, and logical coherence.

Iii. Experimental Results: Breakthrough Performance of the specialized AI model SpineGPT
Based on the Qwen2.5-VL-7B-Instruct model, SpineGPT was fine-tuned in three stages on SpinEMD-450K through the Curriculum Learning framework to gradually enhance its applicability and professionalism in the field of spinal health.
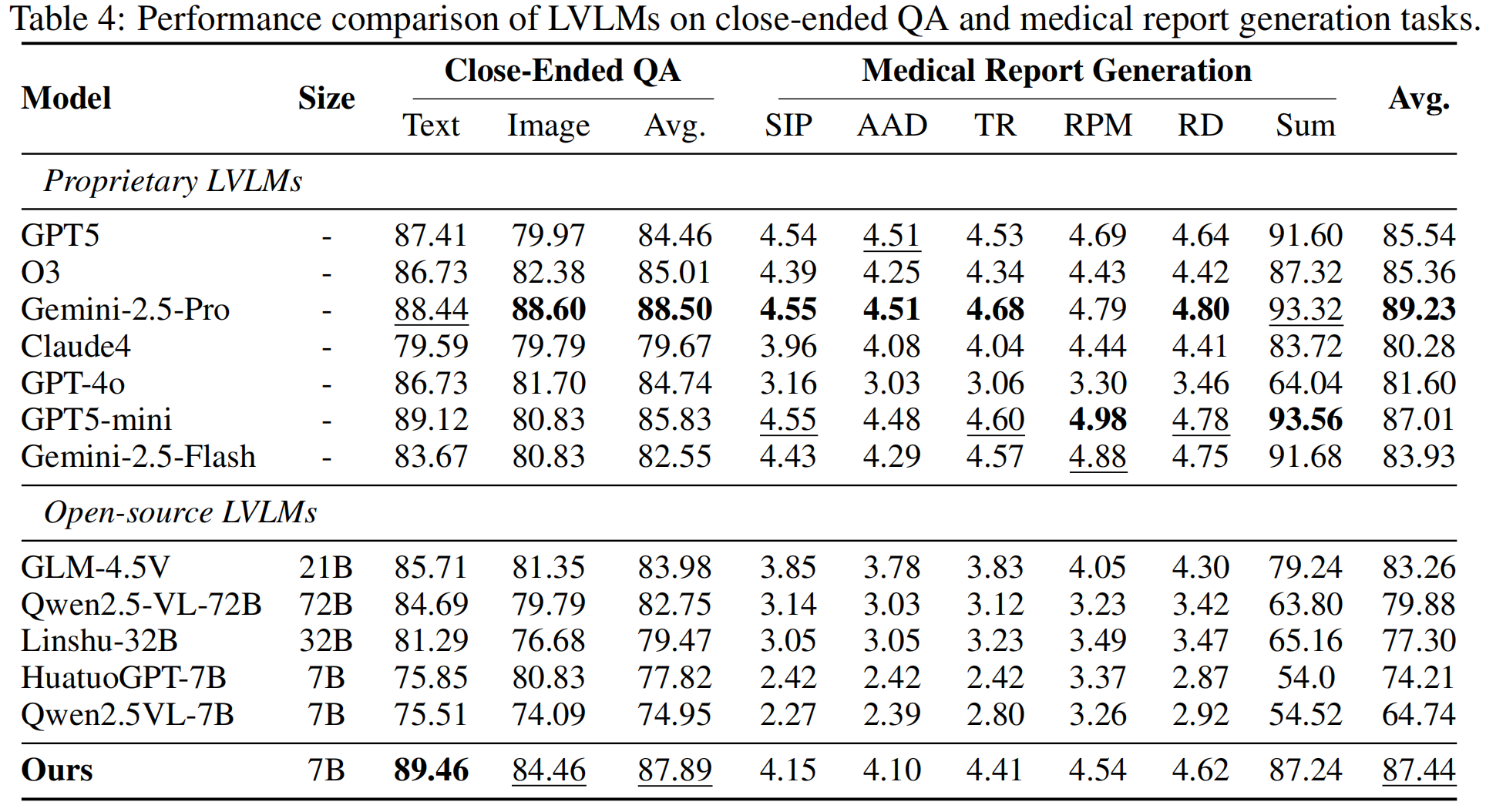
3.Surpassing open source and approaching top proprietary models: SpineGPT achieved an average score of 87.44%, significantly leading all open source large models by more than 4.18 percentage points. In the plain text QA task (89.46%), SpineGPT even outperformed all the evaluated models, including GPT5 (87.41%).
The Importance of Specialized Data (Ablation Experiment) :
When the model was trained only on general medical data, its performance dropped significantly (74.95% vs 65.31%).
After incorporating carefully curated non-spinal general orthopedic data, performance was significantly enhanced (82.14% vs 74.95%), verifying the importance of domain-aligned training data.
Ultimately, after incorporating spine-specific training data (including dialogue, report generation, and long-chain reasoning instructions), the model's performance was further enhanced to 87.89%.
The clinical reporting capability has been significantly enhanced: SpineGPT scored 87.24 points in the medical report generation task, while Qwen2.5-VL-72B only scored 63.80 points and ChatGPT-4o scored 64.04 points.
Case Comparison: In the analysis of the adolescent idiopathic scoliosis case, SpineGPT provided 72 detailed clinical processing procedures, covering complete imaging discovery, AI diagnosis, patient and doctor-oriented treatment recommendations, risk management, and postoperative problem management. In contrast, the reports of ChatGPT-4o are more inclined towards basic diagnoses and treatment suggestions suitable for general medical documents.

Human experts highly recognize that the Pearson correlation coefficient between the report scores given by human experts and the automatic scores given by LLMS ranges from 0.382 to 0.949, and the correlations in most dimensions are above 0.7. This strongly validates the reliability of LLM automatic scoring as an expert judgment agent.

Conclusions and Prospects
This study demonstrates that for a professional field like spinal diagnosis that requires complex anatomical reasoning, the development process of specialized instruction data and clinician intervention is the key to achieving clinical-grade AI capabilities.
The release of SpinEMD-450K and SpineBench provides a highly practical baseline for future AI research. The research team plans to expand the dataset, train models with parameters greater than 7B, and combine reinforcement learning techniques to further deepen direct comparisons with leading proprietary models in order to establish a clearer performance benchmark.